

I respect your privacy. Unsubscribe at any time.
If automated testing was a math formula, it would look something like this:

That is an automated test in a nutshell:
- You take the code you wish to test;
- You perform actions to get it to the right state;
- You check that the state (or value) is as expected.
Let’s refer to the formula above as the testing equation. Here’s how that equation manifests in an actual test:
import { fetchUser } from './fetch-user.js'test('fetches the user by id', async () => { await expect(fetchUser('abc-123')).resolves.toEqual({ firstName: 'John' }) // fetchUser() function + called with "abc-123" = this user object})
These three members of the equation are also the three phases of any test.
In practice, you are often testing code that exists as a part of a larger system. That code may depend on other code or execute side effects that may or may not be relevant to the intention you are trying to test.
Let’s take the fetchUser() function as an example and see how it’s implemented:
import { toCamelCase } from './to-cammel-case.js'export function fetchUser(id: string): Promise<User> { const response = await fetch(`/user/${id}`) const user = await response.json() const normalizedUser = toCamelCase(user) return normalizedUser}
There are a couple of things happening in this function:
- First, it makes an HTTP call to the
/user/:idendpoint to fetch the user; - Then, it reads the response body as JSON in the
userobject. - Finally, it normalizes the
userobject to ensure that all of its keys are in camel case.
All these steps add up to what becomes the fetchUser() function. Using the substitution method, we can replace the fetchUser() function in the equation with the sum of its counterparts:
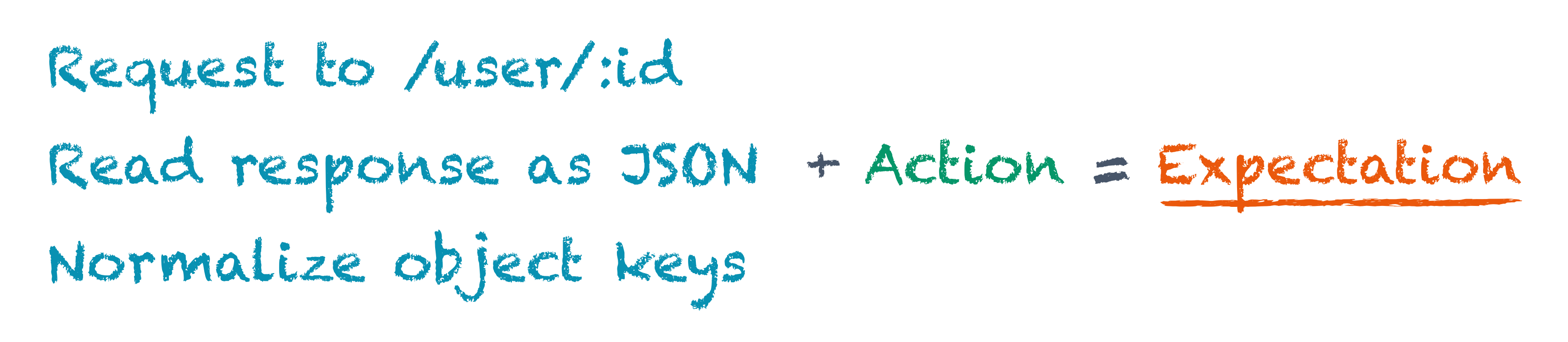
This gives us a complete view on every piece involved in this particular test. While each piece brings its own logic, it is the fetchUser() function that puts it together in a correct order.
Why is this useful? Because . . .
Every member of the testing equation affects the test’s result.
The biggest value you get from tests is knowing when they are supposed to fail. For our fetchUser() function, the test will fail in these cases:
- Network error. If the request to
/user/:idfailed for any reason, none of the dependent code will execute correctly; - Server response. If the server responds with a non-JSON response, or that response is not the object we expect (e.g. an error), the returned user will not match the expected one in test;
- Bugs in
toCammelCase(). If the utility function fails to normalize theuserobject keys, the actual user object still won’t match the expected one.
Knowing this, you are in charge of deciding when this test should fail. Your decision will affect both the reliability of your test and also the behavior(s) that you are testing.
One of the primary things you’d want to do in this case is prevent the network from affecting the test results. The operability and correctness of the server is not the tested function’s concern. The function doesn’t affect server and cannot guarantee its behavior. As such, the test must not fail due to the things that lie outside of the tested code’s concern.
A common way to achieve that is by using API mocking. By mocking the response, you take the network out of the testing equation, transforming it from variable to given. The only things that actually affect the test now are the logic in fetchUser() and its dependency on toCammelCase().
Whenever you take something out of the testing equation, you establish a test boundary.
Test boundaries
The test boundary is the extent of the tested system executed in test.
You can think of the test boundary as an imaginary line you draw through your code telling the test that nothing past that line matters.
Knowing when and how to establish the test boundary is essential to any test.
When done poorly, it leads to brittle and flaky tests that you’d wish to delete (and you probably should). When done correctly, it gives you full control over what it is you are testing and what value the test failures bring you.
The test boundary is inevitably connected to mocking. In fact, mocking at its core is a tool designed to establish that boundary in your tests.
A chisel to a block of marble is what mocking is to your tested code.
By removing the network from the fetchUser() test, you focus that test on the behavior of the function and also its dependency on toCamelCase() (the remaining members of the testing equation). If you also decide to mock the toCamelCase() function, you dial the test’s lens even further, now asserting only the right steps and their sequence in fetchUser().
And here’s where the snug is.
If you chisel the marble enough times, there will be nothing left.
Since the test boundaries help you decide what doesn’t matter in test, overdoing them leads to a test where nothing matters because nothing is actually being tested. This is often referred to as overmocking, which is the state you never want to reach.
That begs a question: Where do I draw the line?
Where to put test boundaries?
The things you “take out” from your tested code vastly depend on the code itself and what you want to test. But I hate “it depends” answers so I will try to give you some actionable pointers that apply to any situation.
You can never miss by starting with The Golden Rule of Assertions, which reads like this:
A test must fail if, and only if, the intention behind the system is not met.
Eliminate the members of the testing equation that are not related to the intention behind the code. If a function is supposed to fetch a user by their ID, its intention is:
- To make a request to the correct endpoint with the correct payload;
- To read, normalize, and return that user response.
Naturally, the part where you draw the boundary is the request and its response.
HTTP requests, side effects (like writing to the file system or interacting with the DOM), and non-deterministic values (like dates or RNG) are some of the common things you always want mocked.
Once you have those taken care off, the test boundary becomes your magnifying glass, and the way you dial it directly affects what kind of test you get. Here’s what I mean.
If you are testing a Component A that depends on a Component B, you have a choice. You can either leave that dependency as-is or mock it out. Neither of those choices is wrong. You simply get a different test as a result. Mocking the dependency allows you to focus on the Component A in what likely be a unit test. Leaving the dependency be, you create an integration test, where the way A and B communicate matters and affects the test results.
Conclusion
I hope you realize and come to love the power the testing boundaries give you when testing. They help you eliminate unwanted code while focusing on the behaviors or integrations that matter.
I am head-deep into my next workshop on Mocking Techniques, where we will dive into the existing mocking techniques in JavaScript! Until then, I will keep you posted on a bunch of other things around boundaries, mocks, and testing in general.
Stay safe and write good tests! 👋